آموزش چهارچوب های داده (دیتا فریم) در R
یک دیتا فریم، یک جدول و یا یک ساختار آرایه مانند دو بعدی است که در آن هر ستون شامل مقادیری از متغیرها می باشد و هر ردیف؛ شامل یک مجموعه از مقادیر هر ستون است.
در ادامه؛ مشخصات یک دیتا فریم آورده شده است:
- نام های ستونها نباید خالی باشد.
- نام های ردیف ها باید خاص باشد.
- دیتای ذخیره شده دیتافریم می تواند به صورت عددی، فاکتور یا نوع کاراکتری باشد.
- هر ستون باید شامل تعداد یکسانی از آیتم های داده باشد.
ایجاد دیتا فریم
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01”, “2013-09-23”, “2014-11-15”, “2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
stringsAsFactors = FALSE
)
# Print the data frame.
print(emp.data)
زمانی که کد بالا را اجرا می کنیم؛ نتیجه زیر را به دست می آوریم:
emp_id emp_name salary start_date
۱ ۱ Rick 623.30 2012-01-01
۲ ۲ Dan 515.20 2013-09-23
۳ ۳ Michelle 611.00 2014-11-15
۴ ۴ Ryan 729.00 2014-05-11
۵ ۵ Gary 843.25 2015-03-27
ساختار دهی دیتا فریم
ساختار دیتا فریم را می توان با استفاده از تابع ()str مشاهده کرد.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01”, “2013-09-23”, “2014-11-15”, “2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
stringsAsFactors = FALSE
)
# Get the structure of the data frame.
str(emp.data)
زمانی که کد بالا را اجرا می کنیم؛ نتیجه زیر را به دست می آوریم:
‘data.frame’: 5 obs. of 4 variables:
$ emp_id : int 1 2 3 4 5
$ emp_name : chr “Rick” “Dan” “Michelle” “Ryan” …
$ salary : num 623 515 611 729 843
$ start_date: Date, format: “2012-01-01” “2013-09-23” “2014-11-15” “2014-05-11” …
خلاصه کردن داده ها در دیتافریم
خلاصه آماری و ماهیت داده ها را می توان با اعمال تابع ()summary به دست آورد:
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01”, “2013-09-23”, “2014-11-15”, “2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
stringsAsFactors = FALSE
)
# Print the summary.
print(summary(emp.data))
زمانی که کد بالا را اجرا کنیم؛ نتیجه زیر حاصل می شود:
emp_id emp_name salary start_date
Min. :1 Length:5 Min. :515.2 Min. :2012-01-01
۱st Qu.:2 Class :character 1st Qu.:611.0 1st Qu.:2013-09-23
Median :3 Mode :character Median :623.3 Median :2014-05-11
Mean :3 Mean :664.4 Mean :2014-01-14
۳rd Qu.:4 3rd Qu.:729.0 3rd Qu.:2014-11-15
Max. :5 Max. :843.2 Max. :2015-03-27
استخراج داده ها از فریم دیتا
استخراج یک ستون خاص از فریم دیتا را می توان با استفاده از نام ستون انجام داد:
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01″,”2013-09-23″,”2014-11-15″,”2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
stringsAsFactors = FALSE
)
# Extract Specific columns.
result <- data.frame(emp.data$emp_name,emp.data$salary)
print(result)
زمانی که کد بالا را اجرا نمایید؛ نتیجه زیر را به دست می آورید:
emp.data.emp_name emp.data.salary
۱ Rick 623.30
۲ Dan 515.20
۳ Michelle 611.00
۴ Ryan 729.00
۵ Gary 843.25
استخراج دو ردیف اول و سپس تمام ستون ها
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
پایگاه داده SQL Server رو قورت بده! بدون کلاس، سرعت 2 برابر، ماندگاری 3 برابر، پولسازی بلافاصله ... دانلود:
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01”, “2013-09-23”, “2014-11-15”, “2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
stringsAsFactors = FALSE
)
# Extract first two rows.
result <- emp.data[1:2,]
print(result)

با اجرای کد بالا، نتایج زیر حاصل می شود :
emp_id emp_name salary start_date
۱ ۱ Rick 623.3 2012-01-01
۲ ۲ Dan 515.2 2013-09-23
استخراج ردیف سوم و پنجم با ستون دوم و چهارم
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01”, “2013-09-23”, “2014-11-15”, “2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
stringsAsFactors = FALSE
)
# Extract 3rd and 5th row with 2nd and 4th column.
result <- emp.data[c(3,5),c(2,4)]
print(result)
اجرای کد بالا، نتیجه زیر را در خروجی ایجاد می کند:
emp_name start_date
۳ Michelle 2014-11-15
۵ Gary 2015-03-27
بسط دادن فریم دیتا
یک فریم دیتا را می توان با اضافه کردن ردیف ها و ستون ها، بسط داد.
افزودن ستون
یک بردار ستونی را با استفاده از نام یک ستون جدید؛ اضافه می کنیم:
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01”, “2013-09-23”, “2014-11-15”, “2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
stringsAsFactors = FALSE
)
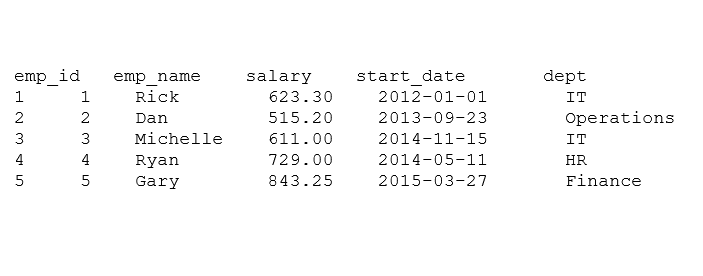
# Add the “dept” coulmn.
emp.data$dept <- c(“IT”,”Operations”,”IT”,”HR”,”Finance”)
v <- emp.data
print(v)
زمانی که کد بالا را اجرا می کنیم؛ نتیجه زیر به دست می آید:
emp_id emp_name salary start_date dept
۱ ۱ Rick 623.30 2012-01-01 IT
۲ ۲ Dan 515.20 2013-09-23 Operations
۳ ۳ Michelle 611.00 2014-11-15 IT
۴ ۴ Ryan 729.00 2014-05-11 HR
۵ ۵ Gary 843.25 2015-03-27 Finance
افزودن ردیف
برای افزودن ردیف های بیشتر به یک فریم دیتای موجود، باید ردیف های جدید را در همان ساختار داده های موجود وارد کنیم و از تابع ()rbind استفاده کنیم.
در مثال زیر یک دیتافریم با ردیف های جدید ایجاد می کنیم و آن را با فریم دیتای موجود ادغام می کنیم تا فریم دیتای نهایی ایجاد شود.
# Create the first data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c(“Rick”,”Dan”,”Michelle”,”Ryan”,”Gary”),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c(“2012-01-01”, “2013-09-23”, “2014-11-15”, “2014-05-11”,
“۲۰۱۵-۰۳-۲۷”)),
dept = c(“IT”,”Operations”,”IT”,”HR”,”Finance”),
stringsAsFactors = FALSE
)
# Create the second data frame
emp.newdata <- data.frame(
emp_id = c (6:8),
emp_name = c(“Rasmi”,”Pranab”,”Tusar”),
salary = c(578.0,722.5,632.8),
start_date = as.Date(c(“2013-05-21″,”2013-07-30″,”2014-06-17”)),
dept = c(“IT”,”Operations”,”Fianance”),
stringsAsFactors = FALSE
)
# Bind the two data frames.
emp.finaldata <- rbind(emp.data,emp.newdata)
print(emp.finaldata)
زمانیکه کد بالا اجرا شود؛ نتیجه زیر ایجاد می شود:
emp_id emp_name salary start_date dept
۱ ۱ Rick 623.30 2012-01-01 IT
۲ ۲ Dan 515.20 2013-09-23 Operations
۳ ۳ Michelle 611.00 2014-11-15 IT
۴ ۴ Ryan 729.00 2014-05-11 HR
۵ ۵ Gary 843.25 2015-03-27 Finance
۶ ۶ Rasmi 578.00 2013-05-21 IT
۷ ۷ Pranab 722.50 2013-07-30 Operations
۸ ۸ Tusar 632.80 2014-06-17 Fianance