
الگوریتم K means چیست؟ 4 رویکرد و 2 روش محاسبه موجود
قبل از این که به الگوریتم خوشه بندی K-means بپردازیم، اول باید بفهمیم که درک داده های مربوط به محصولات، مشتریان، معاملات و . . . تا چه حد برای شرکت های امروزی مهم است. در دنیایی که فناوری تعریف جدیدی برای چشم انداز کسب و کار ارائه کرده است، شرکت ها میلیون ها دلار برای تجزیه و تحلیل داده ها هزینه می کنند تا به الگو هایی دست یابند که به آن ها کمک می کند تا رشد کنند و سودشان را افزایش دهند. گروه بندی اشیاء با هم بر اساس ویژگی ها یکی از اولین کار هایی است که در فرآیند ایجاد چنین الگو هایی دخیل است.
گروه بندی اشیا به شرکت ها کمک می کند تا استراتژی های مختلفی را برای موقعیت های مختلف طراحی کنند. مشتریان، محصولات و معاملات موضوعات اصلی در چنین فرآیند هایی هستند. در واقع گروه بندی مشتریان بر اساس رفتارشان به کسب و کار ها کمک می کند تا محصولات شخصی سازی شده ای را طراحی کنند. گروه بندی محصولات به آن ها کمک می کند تا گزینه های جایگزینی را به مشتریان ارائه دهند. و گروه بندی تراکنش ها به آن ها کمک می کند تا الگو های غیر عادی که نیاز به توجه بیشتری دارند را شناسایی کنند.
این جا است که خوشه بندی انجام می شود. خوشه بندی یا Clustering اساسا یک الگوریتم یادگیری ماشینی بدون نظارت (ML) است که اشیاء را بر اساس ویژگی ها گروه بندی می کند.
شما در این مقاله کاملا متوجه خواهید شد که خوشه بندی K-means در یادگیری ماشین چیست و چطور می توانید آن را با استفاده از پایتون پیاده سازی کنید.
خوشه بندی چیست؟
خوشه بندی، فرآیند گروه بندی نقاط داده است طوری که هر عنصر در یک گروه خاص بیشتر شبیه عناصر همان گروه باشد تا عناصر گروه های دیگر. خوشه بندی به الگوریتم خاصی اشاره نمی کند و فرایند و کاری عمومی است که با استفاده از الگوریتم های بسیاری قابل انجام است. الگوریتم های خوشه بندی معمولا معیاری را برای تعیین کمیت شباهت به طور سیستماتیک تعریف می کنند. خوشه بندی در بسیاری از زمینه ها مثل پردازش تصویر، بازیابی اطلاعات، موتور های توصیه گر، فشرده سازی داده ها و غیره استفاده می شود.
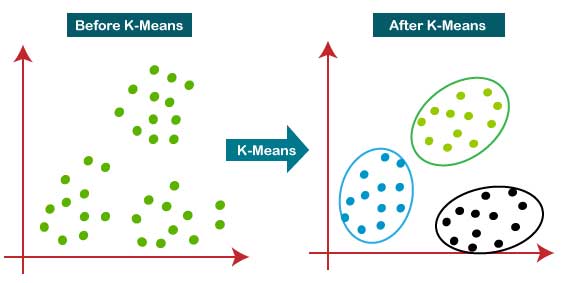
این الگوریتم شباهت را بر اساس ویژگی های اشیایی که خوشه بندی می کند، شناسایی خواهد کرد. این ویژگی ها بر اساس دامنه متفاوت هستند. به طور مثال در مورد یک تصویر، این ویژگی ها مقادیر پیکسلی هستند. در مورد نمایه کاربر، این ویژگی ها جزئیاتی مثل سن، جنسیت، سابقه خرید و غیره هستند. در مورد یک محصول هم دسته، رنگ، قیمت و غیره هستند. خوشه بندی را یک کار بدون نظارت می نامند زیرا هیچ فرآیند آموزشی تحت نظارت کاربری نیست که شامل تهیه داده های برچسب گذاری شده باشد.
الگوریتم های خوشه بندی چطور کار می کنند؟
اکثر الگوریتم های خوشه بندی با محاسبه شباهت بین همه جفت نمونه ها کار می کنند. نحوه محاسبه شباهت و توالی شباهت دوگانه محاسباتی با توجه به نوع الگوریتم خوشه بندی متفاوت است.
توانایی مقیاس بندی برای حجم مجموعه داده ها یک عامل اساسی است که باید در هنگام تصمیم گیری در مورد الگوریتم خوشه بندی برای یک مسئله در نظر گرفته شود. زمان اجرا با تعداد جفت عناصر بالا می رود. در موارد حاد، می تواند متناسب با مجذور حجم داده تغییر کند.
4 رویکرد خوشه بندی
چهار رویکرد رایج برای خوشه بندی وجود دارد: مبتنی بر مرکز، مبتنی بر چگالی ، سلسله مراتبی و مبتنی بر توزیع. بیایید تک تک بررسی شان کنیم.
1-خوشه بندی مبتنی بر مرکز
این روش، نقاط داده را در خوشه های جداگانه بدون هیچ سلسله مراتبی بر اساس مرکز ثقل خوشه سازماندهی می کند. مرکز ثقل در واقع مرکز هندسی یک جسم است. به عبارت ساده، میانگین حسابی تمام نقاطی است که آن شی را در فضای n بعدی تشکیل میدهند. در اینجا، یک خوشه مجموعه ای از نقاط واقع در اطراف یک مرکز است. البته خوشه بندی مبتنی بر مرکز با مشکلاتی از قبیل تخصیص اولیه و نقاط پِرت رو به رو است.
2- خوشه بندی مبتنی بر چگالی
همان طور که از نام آن پیداست، چگالی نقاط یک ناحیه را محاسبه می کند و هر جا که چگالی بالایی پیدا کند، خوشه بندی می کند. در این حالت، خوشه ها می توانند هر شکلی به خودشان بگیرند. خوشه بندی مبتنی بر چگالی زمانی دچار مشکل می شود که داده ها ذاتا واریانس بالایی در چگالی داشته باشند. این روش وقتی بُعد داده ها زیاد است، عملکرد خوبی ندارد.
3- خوشه بندی سلسله مراتبی
این روش درختی از خوشه ها را با امکان قرار گرفتن خوشه هایی در داخل خوشه های بزرگ تر ایجاد می کند. این روش مناسب زمانی است که داده ها یک سلسله مراتب ذاتی را نشان می دهند. خوشه بندی سلسله مراتبی اجازه می دهد تا هر تعداد خوشه را بعد از اجرا انتخاب کنید زیرا تحلیلگر می تواند درخت را در نقطه مورد نیاز بشکند و فقط خوشه های بعد از آن نقطه را در نظر بگیرد.
4- خوشه بندی مبتنی بر توزیع
این روش از مفهوم توزیع های احتمال برای یافتن خوشه ها استفاده می کند. فرض بر این ست که با افزایش فاصله از مرکز، احتمال قرار گرفتن یک نقطه در یک خوشه کاهش می یابد. توسعه دهندگان باید توزیع داده ها را بلد باشند تا از این روش به طور موثر استفاده کنند.
الگوریتم K-means چیست؟
خوشه بندی K-means یک الگوریتم خوشه بندی مبتنی بر مرکز است. این الگوریتم بدون نظارت است زیرا به داده های برچسب گذاری شده متکی نیست. “K” در الگوریتم KMeans نشان دهنده تعداد خوشه ها است. K-means یک الگوریتم تکراری است که میانگین یا مرکز را چندین بار قبل از هم گرایی محاسبه می کند. زمان هم گرایی به تخصیص اولیه خوشه ها بستگی دارد. به طور کلی، پیچیدگی زمانی K-means به این صورت است:
که در آن d تعداد ابعاد، k تعداد خوشه ها و n تعداد عناصر داده است. الگوریتم K-means با محاسبه فاصله هر عنصر داده از مرکز هندسی یک خوشه کار می کند. سپس اگر نقطه ای متعلق به یک خوشه خاص را پیدا کند که به مرکز یک خوشه دیگر نزدیک تر است، خوشه را دوباره مرتب می کند. بعد از آن، مرکز را دوباره محاسبه می کند و این فرآیند را تا زمانی که دیگر تخصیص خوشه ای وجود نداشته باشد، تکرار می کند. بیایید ببینیم این الگوریتم چگونه عمل می کند.
الگوریتم K-means چطور کار میکند؟
الگوریتم K-means یک فرآیند تکراری است که شامل چهار مرحله اصلی است. اجازه بدهید برای درک این مراحل یک مسئله خوشه بندی دو بعدی را در نظر بگیریم. ما نقاط را (x1,y1)، (x2,y2) و… فرض می کنیم. بگذارید با اندازه خوشه 2 شروع کنیم.
تخصیص اولیه
این مرحله هر یک از نقاط را به یک خوشه دلخواه اختصاص می دهد. یک حالت این است که نقاط تصادفی را به عنوان مراکز خوشه اختصاص بدهید و فاصله بین هر یک از این نقاط و مرکز ها را محاسبه کنید.
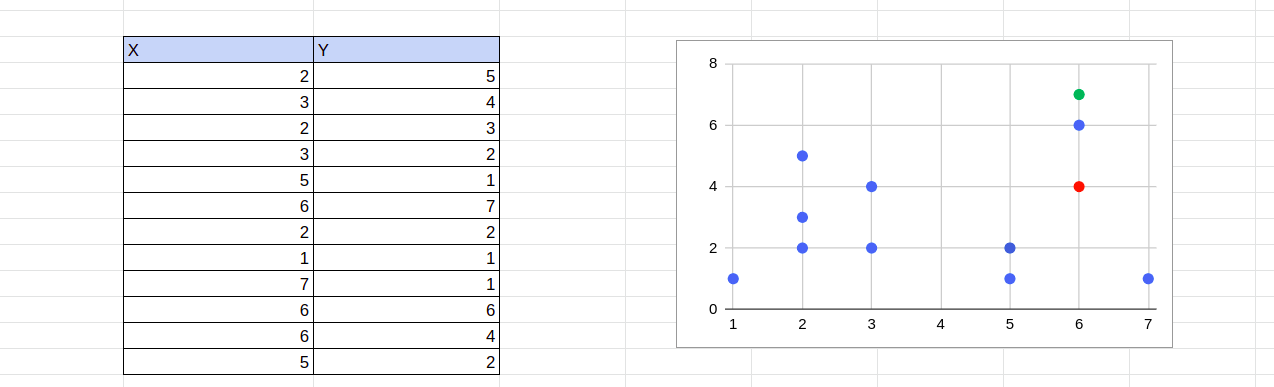
نقاط به خوشه ای که مرکز به آن ها نزدیک تر است اختصاص داده می شود. فاصله با استفاده از فرمول فاصله اقلیدسی محاسبه می شود . به عنوان مثال، اگر x3,y3 یکی از مراکز تخصیص داده شده تصادفی باشد، می توان فاصله بین x1,y1 و x3,y3 را با استفاده از این فرمول محاسبه کرد:
Distance=
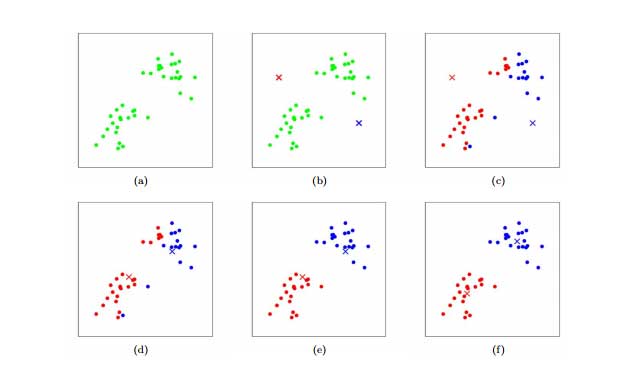
نقاط قرمز و سبز نشان دهنده تخصیص تصادفی اولیه مرکز است. بر اساس این مرکز ها، انتساب اولیه خوشه مثل شکل زیر می شود:
محاسبه مراکز ثقل
این مرحله شامل محاسبه مجدد مرکز ها برای هر خوشه است. مرکز برای یک خوشه با استفاده از میانگین حسابی همه عناصر در آن خوشه محاسبه می شود. مثلا اگر بگوییم که x1، y1، x2، y2 و x3،y3 متعلق به یک خوشه هستند. مرکز آن خوشه به صورت زیر محاسبه می شود:
(xc,yc)=()
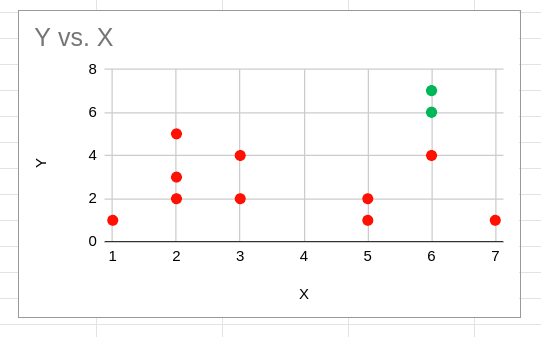
نقاط الماس شکل، همان طور که در زیر نشان داده شده است، تبدیل به مرکز جدید می شوند.
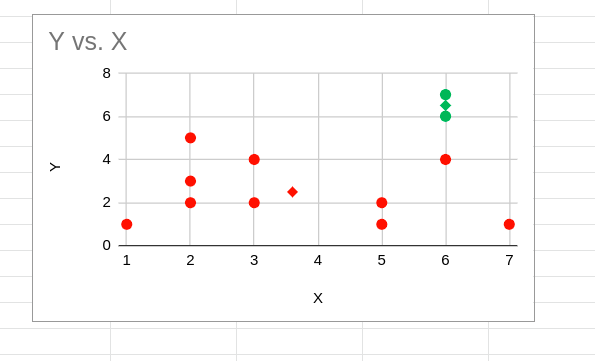
تخصیص مجدد خوشه ها
هنگامی که مراکز جدید برای همه خوشه ها مشخص شد، فاصله بین هر نقطه و مرکز جدید دوباره محاسبه می شود. اگر هر یک از نقاط نزدیک تر به مرکز یک خوشه که در حال حاضر اختصاص داده شده است ، باشد نقاط دوباره تخصیص داده می شوند.
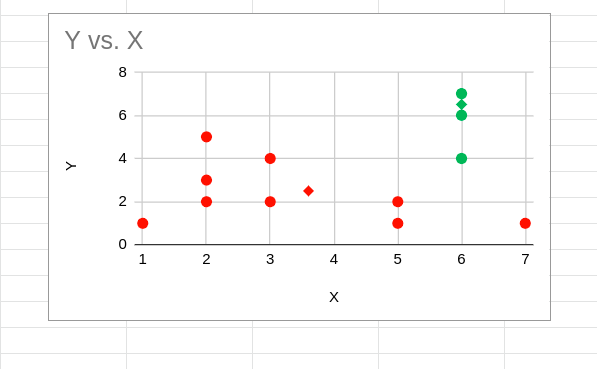
همگرایی
بعد از تخصیص مجدد خوشه ها، مراکز دوباره محاسبه می شوند و این روند تکرار می شود. محاسبه مراکز ثقل و تخصیص مجدد خوشه ها تا زمانی انجام می شود که تخصیص مجدد جدیدی وجود نداشته باشد. خوشه بندی به روش همگرا، در این مورد، به این شکل خواهد بود:
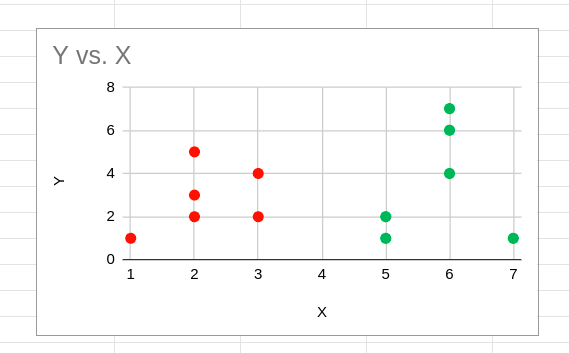
انتخاب تعداد خوشه ها
دو روش متداول برای انتخاب تعداد ایده آل خوشه ها وجود دارد: روش Elbow و روش Silhouette.
روش Elbow
این روش معیاری به نام WCSS (در مجموع مربعات خوشه ای) را محاسبه می کند. این معیار مجموع مجذورات فاصله هر نقطه از مرکز خوشه آن است . نمودار WCSS با توجه به تعداد خوشه ها به عنوان نشانه ای برای انتخاب تعداد بهینه خوشه ها استفاده می شود. توسعه دهندگان خوشه بندی K-means را برای تعداد خوشه های 1 تا n اجرا می کنند و سپس WCSS را برای هر یک از این عملیات محاسبه می کنند. WCSS برای یک خوشه بالاترین خواهد بود و زمانی که تعداد خوشه ها افزایش یابد، کاهش می یابد. نقطه ای که WCSS یک خمیدگی تند مثل آرنج را نشان می دهد، تعداد ایده آل خوشه ها در نظر گرفته می شود.
در ادامه دانلود کنید: آموزش نرم افزار crm از صفر تا صد (20 درس + pdf)
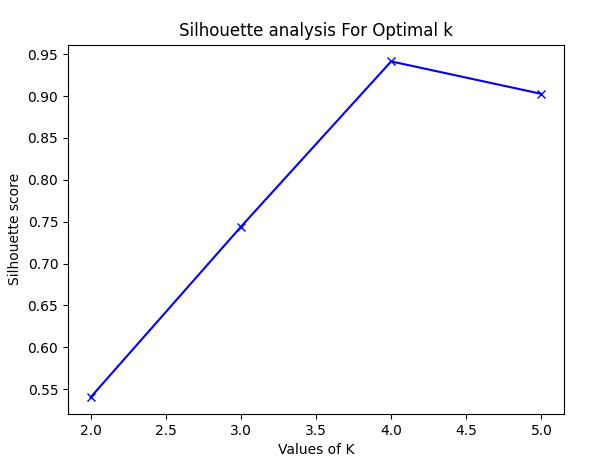
روش Silhouette
3 مهارت برتر مهندسان کامپیوتر! بدون کلاس، سرعت 2 برابر، ماندگاری 3 برابر، پولسازی عالی با هک، متلب و برنامه نویسی... دانلود:

هدف این روش این است که میزان شباهت یک شی با سایر اعضای همان خوشه و میزان جدایی اشیاء از خوشه های دیگر را درک کند. Score Silhouette یا سایه نما برای یک نقطه، با ترکیب میانگین فاصله آن نقطه از سایر نقاط در خوشه (a) و میانگین فاصله آن نقطه با تمام نقاط متعلق به سایر خوشه ها (b) محاسبه می شود. هنگامی که a و b پیدا شدند، اسکور سایهنما برای یک نقطه به صورت زیر محاسبه می شود:
S(i)=
سپس اسکور برای هر نقطه به طور میانگین محاسبه می شود تا اسکور سایه نما پیدا شود. این اسکور به منظور شمارش بهینه برای همه داوطلبان محاسبه می شود و سپس هر کسی که بالاترین اسکور را داشته باشد به عنوان مورد بهینه انتخاب می شود.
یک مثال واقعی از الگوریتم K-means (پیاده سازی K-means با استفاده از پایتون ) این آموزش نحوه پیاده سازی K-means با استفاده از پایتون و یافتن اندازه خوشه بهینه را نشان می دهد. برای انجام این کار، اجازه بدهید یک مشکل رایج در حوزه تجارت الکترونیک را در نظر بگیریم. خوشه بندی مشتریان بر اساس ویژگی های جمعیت شناختی و عادات خرج کردن آن ها یک عمل رایج در حوزه تجارت الکترونیک است. برای ساده تر کردن مثال، در این جا از دو ویژگی استفاده می کنیم: سن مشتری و میانگین خرج شان در ماه.
1-برای انجام این کار، اجازه بدهید از یک کتابخانه یادگیری ماشین پایتون به نام scikit-learn و یک کتابخانه رسم نمودار به نام matplotlib استفاده کنیم. اول کتابخانه ها را با استفاده از دستور های import داده شده در زیر مقدار دهی اولیه کنید:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
2- مرحله بعد نوبت تعریف فریمورک داده ورودی است. در این جا اولین ویژگی سن و ویژگی دوم میانگین خرج ماهانه به روپیه هند (INR) است. برای ساده تر شدن، اجازه بدهید آرایه را در خود کد مقدار دهی اولیه کنیم. ما در این جا 16 نقطه داده داریم:
raw_features = np.array([[22,200],[24,200],[24,200],[20,800],[24,800],[24,800],[25,200],[54,200],[24,200],[54,200],[50,800],[53,800],[24,800],[55,800],[53,800],[50,800]])
3- سپس نقاط داده را یکدست می کنید طوری که تغییرات در یک ویژگی، تغییرات در سایر ویژگی ها را تحت الشعاع قرار ندهد.
scaler = StandardScaler()
features = scaler.fit_transform(raw_features)
4- یک حلقه for را برای آزمایش خوشه بندی K-means برای تعداد خوشه های متنوع از 2 تا 6 پیاده سازی کنید. سپس مجموع مربع ها را محاسبه و آن را بر اساس تعداد خوشه ها رسم می کنیم تا تعداد بهینه خوشه ها را مشخص کنیم.
sse = []
s_scores=[]
for i in range(2,6):
kmeans = KMeans(init = **”random”** ,n_clusters = i,n_init = 10,max_iter = 300,random_state = 42)
kmeans.fit(features)
sse.append(kmeans.inertia_)
s_scores.append(silhouette_score(features, kmeans.labels_))
5- از کتابخانه matplotlib برای رسم نمودار مجموع مربع ها و تعداد خوشه ها استفاده کنید.
plt.style.use( **”fivethirtyeight”** )
plt.plot(range(1, 6), sse)
plt.xticks(range(1, 6))
plt.xlabel( **”Number of Clusters”** )
plt.ylabel( **”SSE”** )
plt.show()
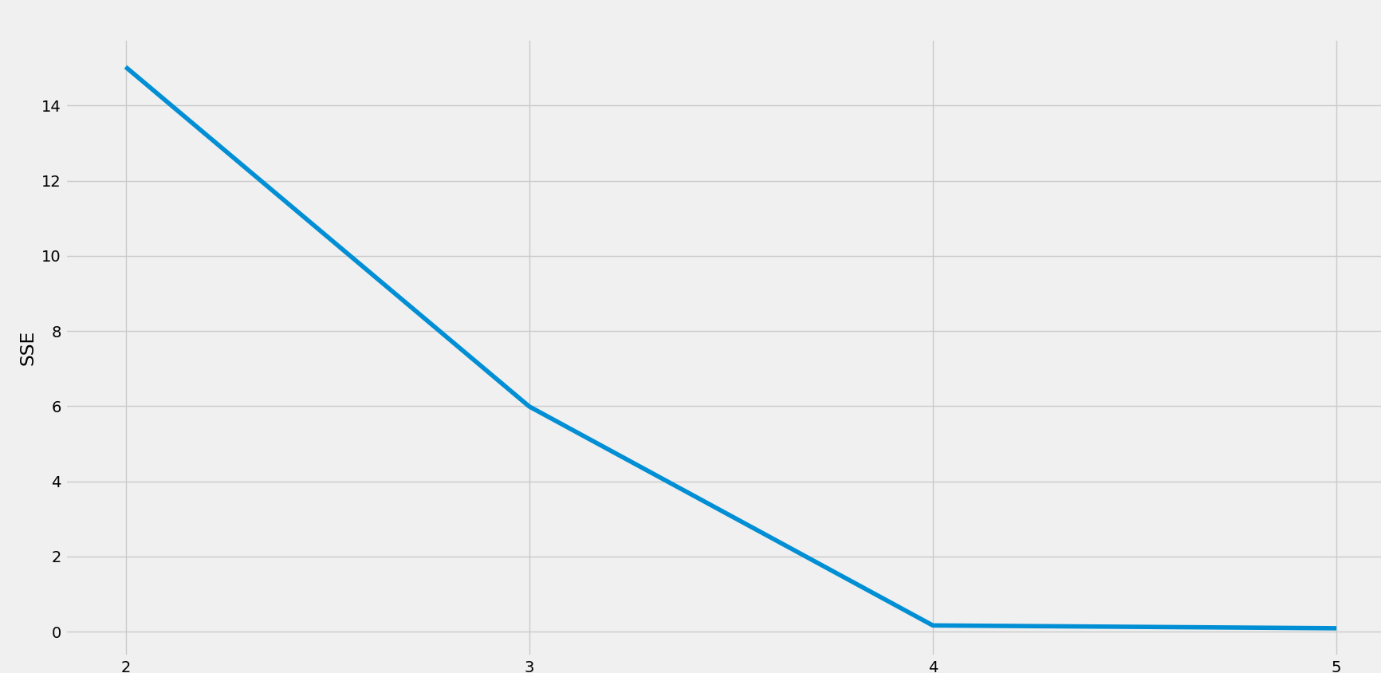
6- اجرای کد بالا منجر به ایجاد نموداری می شود که می توانیم از آن برای شناسایی بهینه تعداد خوشه ها استفاده کنیم.
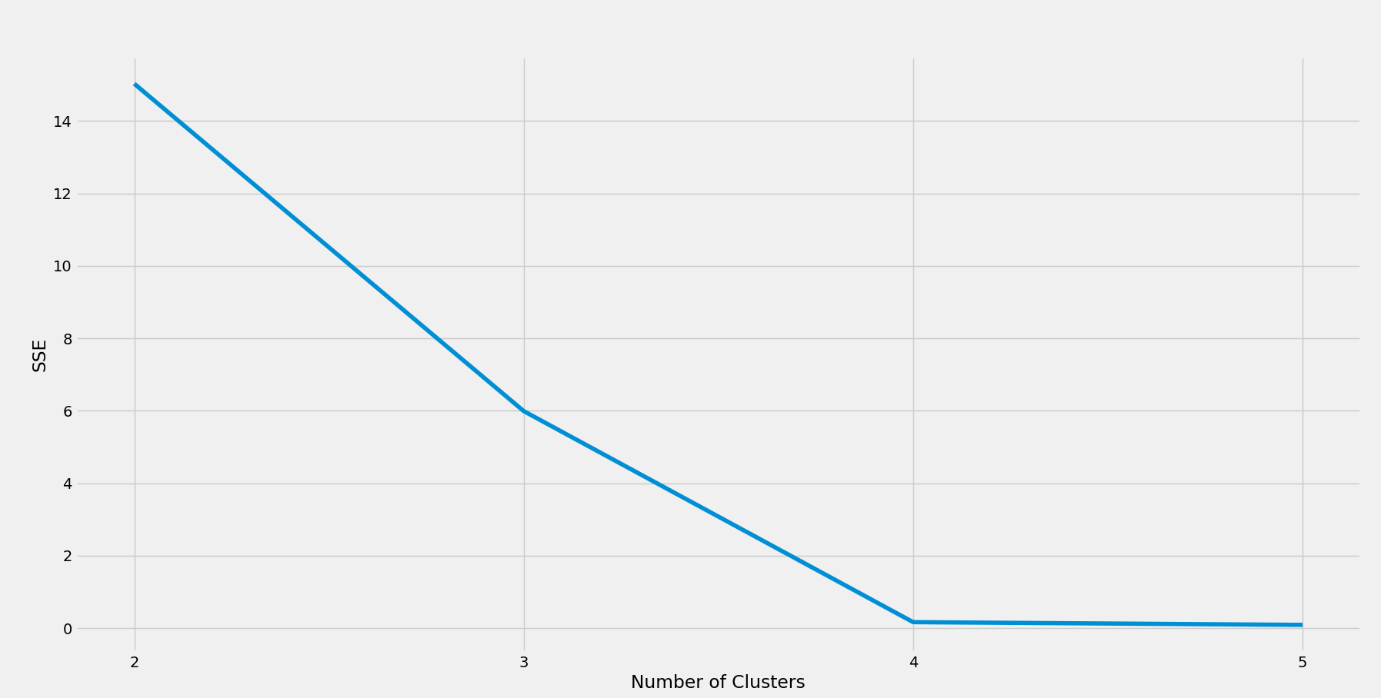
این نمودار یک “آرنج” متمایز را در عدد 4 نشان می دهد. بنابراین تعداد بهینه خوشه ها در این جا 4 تاست. با داشتن کمی آگاهی نسبت به دامنه، یک دانشمند داده می تواند این عدد را به صورت چهار حالت توضیح بدهد؛ خرج کم – سن بالا، خرج کم – سن کم، سن بالا – خرج بالا، و سن بالا – خرج کم مشتریان. اما چنین توضیحاتی ممکن است همیشه امکان پذیر نباشد و اسکور بهینه خوشه ها بر اساس مشخصات مشکل متفاوت باشد. این تمام چیزی است که برای اجرای الگوریتم K-means در پایتون وجود دارد. فریمورک های scikit-learn و matplotlib استفاده از خوشه بندی در پایتون را بسیار آسان می کنند.
دانلود کنید در کنار این مطلب: آموزش مهندسی کامپیوتر از صفر با 8 درس رایگان
چرا خوشه بندی مهم است؟
همان طور که گفتیم، خوشه بندی یک الگوریتم یادگیری ماشینی بدون نظارت است که به گروه بندی اشیاء بر اساس شباهت کمک می کند. این الگوریتم به طور گسترده در بسیاری از حوزه های صنعتی برای تجزیه و تحلیل داده های اکتشافی استفاده می شود که در زمینه هایی مثل تقسیم بندی مشتری، موتور های توصیه گر، جستجوی شباهت و غیره مفید است. با این حال، خوشه بندی تنها تکنیکی نیست که می تواند برای حل این مشکلات استفاده شود. راه دیگر برای حل چنین مشکلی این است که برای هر شیء بر اساس ویژگی های آن ها، جان شان یاembedding هایی ایجاد کنید.
شبکه های آموزشی مبتنی بر یادگیری عمیق می توانند جانشان چند بُعدی برای اشیاء با تعداد زیادی ویژگی ایجاد کنند. این جانشان ها، همراه با یک پایگاه داده برداری خوب، می توانند مشکلات مبتنی بر شباهت را با کنترل بهتری حل کنند.
در کنار این مطلب دانلود کنید: آموزش کامل دیجیتال مارکتینگ با 20 درس + PDF



