Data Science چیست؟ کاربردها، الگوریتم های مورد استفاده+ 2 مثال عملی

Data Science یا علم داده به استخراج دانش از داده هایی می گویند که با استفاده از روش های مختلف جمع آوری می شوند. شما به عنوان یک دانشمند داده، یک مسئله تجاری پیچیده را انتخاب می کنید، در موردش تحقیق می کنید، آن را به داده تبدیل و سپس از آن داده ها برای حل مشکل استفاده می کنید. این برای شما چه معنایی دارد و چه طور و از کجا شروع می کنید؟
تنها چیزی که نیاز دارید درک واضح و عمیق از دامنه یک کسب و کار و داشتن خلاقیت بالا است که بدون شک شما آن را دارید. بخش قابل توجهی از جاذبه علم داده مربوط به کلاه برداری، به ویژه کلاه برداری اینترنتی است. در چنین مواردی، دانشمندان داده الگوریتم هایی را برای شناسایی تقلب و جلوگیری از آن با استفاده از مهارت هایی که دارند ایجاد می کنند. (منبع کمکی مطلب)
در این مقاله آموزش علم داده، همه چیز از جمله زمینه های شغلی برای دانشمندان داده، برنامه های کاربردی علم داده در دنیای واقعی و نحوه شروع کار با در این حوزه را از اول یاد خواهید گرفت. پس با مسئولیت های یک دانشمند داده شروع خواهیم کرد.
درکنار این مطلب حتما نیاز خواهید داشت: آموزش هوش تجاری از صفر تا صد با 30 درس
یک دانشمند داده چه می کند؟
دانشمندان داده در حوزه های مختلفی کار می کنند که هر کدام به منظور یافتن راه حل برای مشکلات بسیار مهم است و نیاز به دانش خاصی دارند. این حوزه ها شامل جمع آوری داده ها، آماده سازی، استخراج و مدل سازی و نگهداری مدل می باشند. دانشمندان داده با استفاده از الگوریتم های یادگیری ماشینی، داده های خام را به معدن با ارزشی از اطلاعات تبدیل می کنند که به سؤالات کسب و کار هایی که به دنبال راه حل برای سؤالات شان هستند، پاسخ می دهد. هر یک از زمینه ها عبارتند از:
- اکتساب داده: دانشمندان داده؛ داده ها را از تمام منابع خام، مثل پایگاه های داده و فایل های مسطح می گیرند. سپس، آن ها را یکی یکی فرمته می کنند و آن را به چیزی که به عنوان ” انبار داده” شناخته می شود، تحویل می گیرند. انبار داده یا Data Warehouse سیستمی است که به کمک آن می توان داده ها را به راحتی برای استخراج اطلاعات استفاده کرد. این مرحله که با نام ETL هم شناخته می شود، با برخی ابزار ها مثل Talend Studio، DataStage و Informatica قابل انجام است.
- آماده سازی داده ها: این مهم ترین مرحله است و 60 درصد از زمان یک دانشمند داده صرف آن می شود، زیرا اغلب داده ها “ناخالص” یا برای استفاده نامناسب هستند و باید مقیاس پذیر، سازنده و معنادار باشند. در واقع، این آماده سازی پنج مرحله فرعی دارد:
1-پاک کردن داده ها: این مرحله مهم است زیرا داده های بد می تواند منجر به مدل های بد شود. طی فرایند پاک سازی مقادیر از دست رفته و مقادیر null یا void که ممکن است باعث از کار افتادن مدل ها شوند، کنترل می شوند. این مرحله در نهایت روی تصمیمات تجاری و بهره وری تاثیر مثبتی دارد.
2- تبدیل داده ها: داده های خام را می گیرد و با عادی سازی، آن ها را به خروجی های دل خواه تبدیل می کند. این مرحله می تواند مثلا از نرمال سازی حداقل – حداکثر یا عادی سازیz score استفاده کند.
3- کنترل داده های پِرت: این مرحله زمانی اتفاق می افتد که برخی از داده ها خارج از محدوده بقیه داده ها قرار می گیرند. یک دانشمند داده با استفاده از تجزیه و تحلیل اکتشافی، به سرعت از نمودار ها و نقشه ها استفاده می کند تا تعیین کند که با داده های پرت چه کاری انجام دهد و ببیند چرا آن ها آنجا هستند. اغلب برای کشف تقلب از داده های پرت استفاده می شود.
4- یکپارچه سازی داده ها: در این مرحله، دانشمند داده اطمینان حاصل می کند که داده ها دقیق و قابل استفاده باشند.
5- کاهش داده ها: در این مرحله چندین منبع داده در یک منبع جمع آوری می شوند، قابلیت های ذخیره سازی افزایش می یابد، هزینه ها کاهش می یابند و داده های تکراری و اضافی حذف می شوند.
6– داده کاوی: در این مرحله، دانشمندان داده الگو های داده و روابط را برای اتخاذ تصمیمات تجاری بهتر کشف می کنند. داده کاوی، یک فرآیند کشف برای به رسیدن به درک پنهان و مفید است که معمولا به عنوان تجزیه و تحلیل داده های اکتشافی شناخته می شود. داده کاوی برای پیش بینی روند های آتی، شناخت الگو های مشتری، کمک در تصمیم گیری، تشخیص سریع تقلب و انتخاب الگوریتم های صحیح مفید است. نرم افزار Tableauبرای داده کاوی بسیار مناسب است.
7– ساخت مدل: این مرحله فراتر از داده کاوی ساده است و نیاز به ساخت یک مدل یادگیری ماشینی دارد. این مدل با انتخاب یک الگوریتم یادگیری ماشینی که مناسب داده ها، بیان مسئله و منابع موجود است، ساخته می شود.
همچنین بخوانید: معرفی اجزای اصلی و مهم Spss برای یادگیری بهتر سطح مقدماتی
الگوریتم های یادگیری ماشینی که توسط دانشمندان داده استفاده می شود
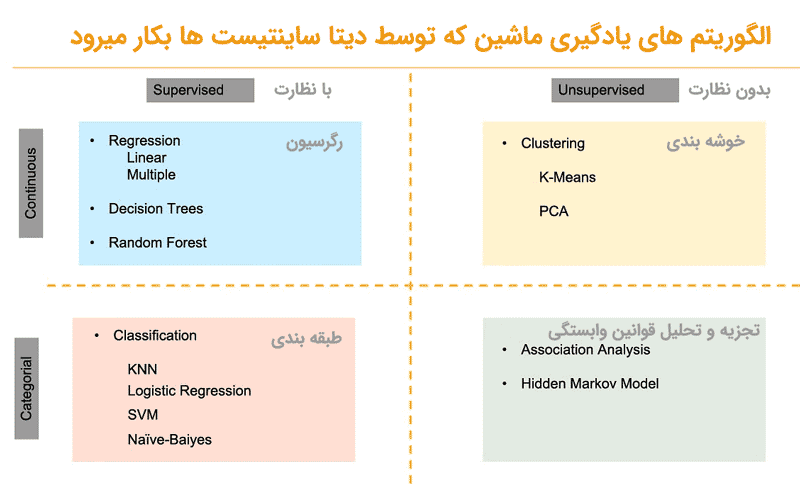
دو نوع الگوریتم یادگیری ماشین وجود دارد: نظارت شده و بدون نظارت:
1-نظارت شده یا Supervised: الگوریتم یادگیری نظارت شده زمانی استفاده می شود که داده ها برچسب گذاری شده اند و دو نوع هم دارد:
- رگرسیون: زمانی که نیاز به پیش بینی مقادیر پیوسته دارید و متغیر ها به صورت خطی وابسته هستند، الگوریتم های مورد استفاده رگرسیون خطی و چند گانه، درخت تصمیم و جنگل تصادفی خواهند بود.
- طبقه بندی: هنگامی که لازم است مقادیر مطلق را پیش بینی کنید، می توانید از برخی از الگوریتم های طبقه بندی مورد استفاده مثل KNN، رگرسیون لجستیک، SVM و Naïve- Bayes استفاده کنید.
- بدون نظارت: الگوریتم های یادگیری بدون نظارت زمانی استفاده می شوند که داده ها بدون برچسب هستند و هیچ داده برچسب گذاریشده ای برای یادگیری وجود ندارد که دو نوع دارد:
- خوشه بندی: این الگوریتم متد تقسیم اشیایی است که بین شان مشابه و غیر مشابه وجود دارد. معمولا از الگوریتم های خوشه بندی K-Means و PCA استفاده می شود.
- تجزیه و تحلیل قوانین وابستگی: برای کشف روابط جالب بین متغیر ها، می توان از الگوریتم Apriori و Hidden Markov Model استفاده کرد.
- تعمیر و نگهداری مدل: بعد از جمع آوری داده ها و انجام مرحله استخراج و ساخت مدل، دانشمندان داده باید دقت مدل را بالا ببرند. برای این منظور، آن ها مراحل زیر را انجام می دهند:
1-ارزیابی: نمونه ای را گهگاهی به کمک داده ها اجرا می کنند تا مطمئن شوند که مدل دقیق باقی می ماند.
2- آموزش مجدد: اگر نتایج ارزیابی مجدد درست نباشد، دانشمند داده باید الگوریتم را مجددا آموزش دهد تا دوباره نتایج صحیح حاصل شوند..
3- بازسازی: اگر مرحله آموزش مجدد با شکست مواجه شد، باید بازسازی صورت گیرد.
همان طور که می بینید، علم داده فرآیندی پیچیده و متشکل از مراحل مختلف است که برای دستیابی به نتایج مداوم و عالی از تمام پتانسیلش استفاده خواهد کرد.
دانلود ۸ درس کاربردی آموزش تجزیه و تحلیل اطلاعات با نرم افزار آماری SAS
حالا که متوجه شدید یک دانشمند داده چه می کند، اجازه بدهید در بخش بعدی آموزش علم داده به چند نمونه از علم داده در عمل نگاهی بیندازیم.
دو نمونه از علم داده در عمل
علم داده از داده های خامش برای کمک به حل مسائل استفاده می کند. در هر یک از این دو مثال، داده ها به حل سوالی کمک کردند که مردم دچار مشکل کرده بود. در مورد اول، یک بانک باید بفهمد چرا مشتریانش این بانک را ترک می کنند، این مثال بر داده کاوی با استفاده از Tableau تمرکز دارد. مثال دوم کنجکاوی در مورد اینکه کدام کشور ها بالاترین میزان شادی را داشتند، بود. این مثال بر ساخت مدل تمرکز دارد. بدون علم داده، رسیدن به جواب این دو سوال غیر ممکن بود.
مثال اول: میزان انصراف مشتری از بانک
3 مهارت برتر مهندسان کامپیوتر! بدون کلاس، سرعت 2 برابر، ماندگاری 3 برابر، پولسازی عالی با هک، متلب و برنامه نویسی... دانلود:

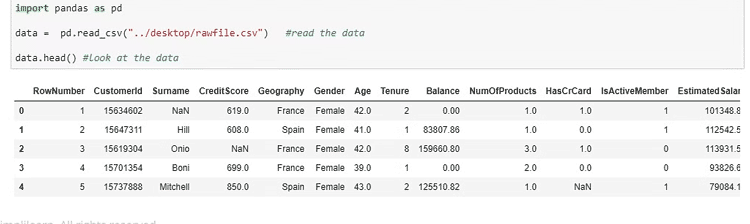
در این نمونه یک بانک در حال انجام پاکسازی داده ها با استفاده از پایتون است. مشتری یک فایل CSV را بارگیری می کند و مقادیر از دست رفته را در برخی از زیر مجموعه ها مثل فیلد جغرافیا کشف می کند. در این مورد، دانشمند داده باید مقادیر خالی را با چیزی پر کند تا مجموعه داده را یکنواخت کند، بنابراین با نوشتن یک کد برای انجام این کار، داده ها با امتیاز “میانگین” پر می شوند. در غیر این صورت، داده های آماری به درد نمی خورند.
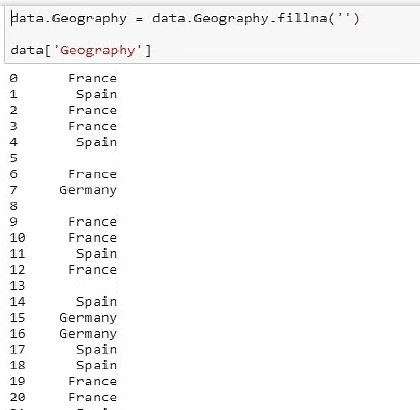
با این حال، یک دانشمند داده می تواند اقدامات دیگری را در صورت عدم وجود داده انجام دهد. مثلا می توان کل ردیف را رها کرد اما این زیاده روی است و ممکن است نتایج مطالعه را تحریف کند.

اگر همه ستونها خالی باشند، می توان آن ها را رها کرد. علاوه بر این، زمانی که 10 تا 20 ردیف وجود دارد، و پنج تا هفت خالی است، می توان پنج تا هفت را رها کرد بدون این که نگران تغییر فاحش نتایج بود.
بعد از پاکسازی داده ها، دانشمند داده آماده است تا از داده ها برای داده کاوی استفاده کند.
حالا، دانشمند داده از Tableau برای بررسی نرخ خروج مشتریان بانک بر اساس جنسیت ، موجودی کارت اعتباری و جغرافیا استفاده می کند تا ببیند آیا این ها بر این نرخ تأثیر می گذارند یا خیر.
فوق العاده کاربردی در کنار دیتا ساینس: الگوریتم K means چیست؟ 4 رویکرد و 2 روش محاسبه موجود
Tableau از سیستم کشیدن و رها کردن (Drag & Drop) برای تجزیه و تحلیل داده ها استفاده می کند، بنابراین، برای تجزیه و تحلیل جنسیت ، دانشمند داده “Exited” را در بخش “Dimensions” Tableau و “Gender” را در بخش “Measures” آن قرار می دهد.
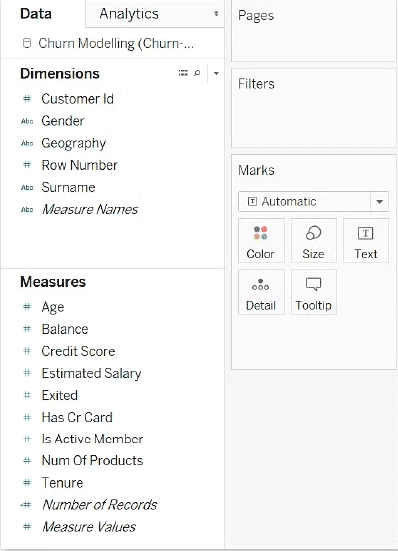
با این کار دو ستون یکی برای مردان و یکی برای زنان، و دو مقدار، 0 برای کسانی که خارج نشدند، و 1 برای کسانی که خارج نشدند ایجاد می شود.
سپس یک نمودار میله ای درصد مقادیر را نشان می دهد. داده ها تفاوت بین زن و مرد را نشان می دهند.
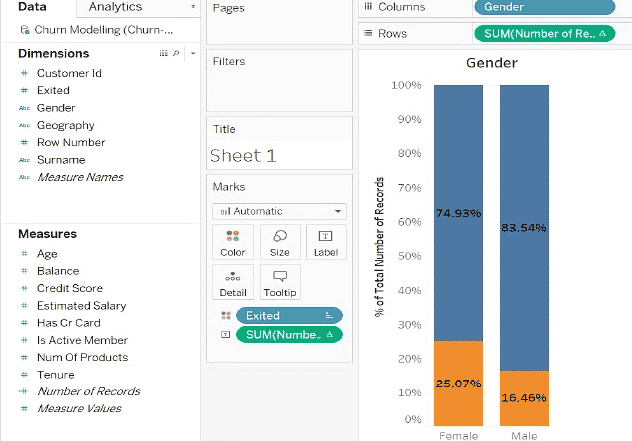
انجام همین کار برای کارت های اعتباری هیچ تاثیری را نشان نمی دهد، اما جغرافیا چرا!
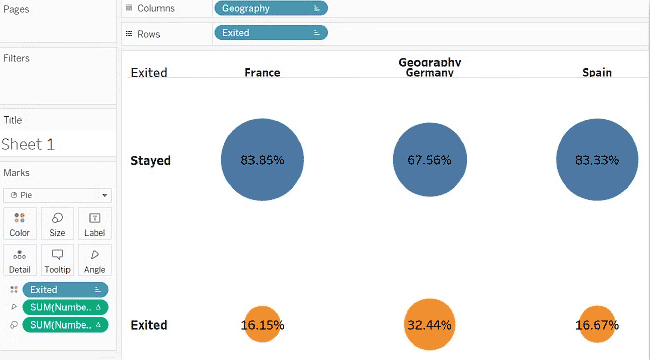
در نتیجه، این مطالعه نشان می دهد که بانک باید جنسیت و مکان مشتریانش را در هنگام تجزیه و تحلیل چگونگی حفظ بهتر آن ها در نظر بگیرد. بنابراین، به لطف علم داده، بانک اطلاعات مهمی در مورد رفتار مشتری می آموزد.
مثال دوم: پیش بینی میزان شادی در جهان
پیش بینی خوشبختی جهان یک هدف غیر ممکن به نظر می رسد، نه؟ اما به لطف علم داده، این طور نیست! با استفاده از ساخت مدل رگرسیون خطی چندگانه، امکان ارزیابی آن وجود دارد.
برای انجام این کار، اول باید یک سری کمیت ها را در نظر گرفت. در این مورد، این کمیت ها رتبه شادی، ارزش شادی، کشور ، منطقه، اقتصاد، خانواده، سلامت، آزادی، اعتماد و سخاوت هستند. به همه آن ها نیازی نیست اما برخی باید برای ساخت و آموزش مدل باشند.
هر زبان برنامه نویسی را از اینجا رایگان می توانید یاد بگیرید
با استفاده از پایتون، دانشمند داده کتابخانه هایی مثل پانداها، نومپی ها و اسکلرن ها را ایمپورت می کند. داده ها به عنوان فایل های CSV از سال های 2015، 2016 و 2017 ایمپورت می شوند. سپس، دانشمند می تواند سه داده را به هم متصل کند یا برای هر CSV یک مدل بسازد. در نهایت، head() کشور های برتر با بالاترین امتیاز شادی را نشان می دهد.
نمودار ها و نقشه هایی در پایتون به وجود می آیند تا نشان دهند کدام کشور ها شادترین و کدام کشور ها کمتر شاد هستند. نمودار پراکندگی ارتباط بین رتبه شادی و امتیاز شادی را نشان می دهد که معکوس است.
زبان اسمبلی چیست؟ معایب و مزایا و چرا باید یاد بگیریم؟
وقتی پردازش داده ها به پایان رسید، می توان نام کشور ها را حذف و مهم ترین عوامل تعیین کننده خوشبختی در جهان را ترسیم کرد. همان طور که تصور می کنید، بالاترین امتیاز، امتیاز شادی است. مطابق تجزیه و تحلیل، دومین عنصر مهم اقتصاد و سپس خانواده و سلامت است . به لطف عملکرد بسیار دقیق ساخت مدل رگرسیون خطی چندگانه پایتون، حالا می توانیم میزان شادی جهان را پیش بینی کنیم!