اتریبیوت چیست؟ انواع کاربردها و هر چیزی که باید بدانید

ممکنه هنگام یادگیری یک زبان برنامه نویسی یا بررسی محموعه داده های بزرگ در درک ویژگی های داده به مشکل خورده باشید و به احتمال زیاد سوالات زیادی برایتان پیش آمده باشد. ویژگی ها یا همان اتریبیوت های داده مفاهیم ساده ای هستند اما معنای آنها ممکنه در شلوغی داده ها محو و گم شود.
هدف این مقاله تعریف واضح اتریبیوت های داده، انواع مختلف، نمایش نمونه ها در یک پایگاه داده ساده و همچنین توضیح نقش آنها در HTML، Python، jQuery، GIS و Six Sigma است.
تعریف و توصیف اتریبیوت
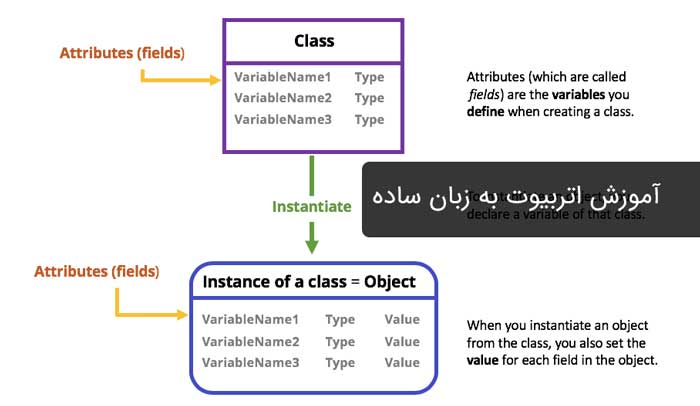
یک اتریبیوت (Attribute) که به آن صفت یا ویژگی داده نیز گفته می شود، به طور خلاصه یک توصیف کننده تک مقداری برای یک نقطه داده یا شی داده است. اغلب به عنوان یک ستون در جدول داده در نظر گرفته می شود اما علاوه بر این می تواند به یک قالب یا عملکرد خاص برای اشیا در زبان های برنامه نویسی مانند پایتون اشاره کند.
مهم اینه که تشخیص دهیم که یک اتریبیوت، داده ایی است که سایر داده ها را توصیف می کند، نباید آن را یک جز خارج از مجموعه داده تصور کنید. بنابراین اتریبیوت روشی است که بخشی از داده ها را برای توصیف قسمت های دیگر استفاده می کنیم.
برای مثال تصور کنید که میزان بارش 10 شهر در 2 کشور را بررسی می کنید. اگر می خواهید روی میزان بارش بر اساس شهرها تمرکز کنید، نام کشور یکی از اتریبیوت های شهرها است. شهرها و کشورها هر دو داده هستند اما یکی دیگری را توصیف می کند.
انواع اتریبیوت ها
3 نوع مختلف برای ویژگی های داده وجود دارد.
Date یا تاریخ: تاریخ یک سال و ماه معین است.
Text یا متن: بیشتر اوقات به عنوان ” stringیا رشته” نیز شناخته می شود و ترکیبی از حروف یا سایر نمادها به جای عدد است.
Boolean یا بولین: یک مقدار دوتایی برای داده های درست یا غلط است که با TRUE یا FALSE شناخته می شوند و با YES یا NO به متن و یا 1 و 0 به عدد منتقل می شوند. به زبان ساده داده باینری است.
نکته: مقادیر عددی به عنوان اندازه ها در نظر گرفته می شوند زیرا می توانند سطرهای داده را از نظر ریاضی دستکاری کنند. آنها جز اتریبیوت های aggregate نیستند.
نمونه ای از اتریبیوت های داده در پایگاه داده ها
پایگاه داده نمونه زیر را برای میزان بارش در نظر بگیرید، با استفاده از این مثال اتریبیوت ها یا ویژگی ها را مشخص می کنیم.
| ماه | روز | کشور | شهر | میزان بارش (سانتی متر) |
|---|---|---|---|---|
| ژانویه | 24 | آمریکا | هیوستون | 13 |
| فوریه | 24 | آمریکا | نیویورک | 12 |
| مارس | 14 | آمریکا | اورلندو | 15 |
| آوریل | 14 | آمریکا | بوستون | 12 |
| می | 4 | آمریکا | فینیکس | 10 |
| ژوئن | 24 | فرانسه | تولون | 14 |
| جولای | 24 | فرانسه | مارسی | 19 |
| آگوست | 14 | فرانسه | پاریس | 10 |
| سپتامبر | 14 | فرانسه | بوردو | 24 |
| اکتبر | 4 | فرانسه | دیژون | 2 |
این پایگاه داده میزان بارندگی را برای 10 شهر در دو کشور طی 10 ماه نشان می دهد. اما توجه داشته باشید که نمی دانیم که این ماه ها همه در یک سال بوده اند یا نه. علاوه بر این گرچه روزها برای هر دو کشور یکسان است اما این روزها در یک ماه در هر دو کشور یکی نیستند. این سوال پیش می آید: در این مجموعه داده چه چیزی را توصیف می کنیم؟
برای فهمیدن این موضوع باید ببینیم چه داده هایی سطرها را از ی متمایز می کند، در واقع چه چیزی هر سطر را منحصر به فرد می کند. وقتی بفهمیم چه چیزی هرگز تکرار نمی شود، پس می فهمیم که اطلاعات چگونه ثبت شده است. یک راه آسان برای تجسم سازی آن مثال زمان است. اگر هر سطر یک لحظه در زمان را نشان دهد پس هیچ کدام از آنها تکرار نمی شود.
حتما دانلود کنید: آموزش صفر تا صد جی کوئری (رایگان)
در این مجموعه داده هر ماه و هر شهر فقط یک بار دیده می شوند. بنابراین می توان گفت که آنها شناسه های منحصر به فرد برای هر سطر هستند. سایر ستون های کشور، روز و میزان بارش ستون های ماه و شهر را توصیف می کنند.
چون سایر فیلدها مانند “کشور” و “روز” ورودی های تکراری دارند یا مانند “میزان بارش” به عنوان یک مقدار عمل می کنند، برای شناسایی سطر مناسب نیستند. می توانیم بگوییم که مجموعه داده به ماه و شهر نرمال سازی شده است.
در اینجا روش بهتری برای مشاهده داده ها وجود دارد که در درک ویژگی ها کمک می کند:
| ماه | شهر | روز | کشور | میزان بارش (سانتی متر) |
|---|---|---|---|---|
| ژانویه | هیوستون | 24 | آمریکا | 13 |
| فوریه | نیویورک | 24 | آمریکا | 12 |
| مارس | اورلندو | 14 | آمریکا | 15 |
| آوریل | بوستون | 14 | آمریکا | 12 |
| می | فینیکس | 4 | آمریکا | 10 |
| ژوئن | تولون | 24 | فرانسه | 14 |
| جولای | مارسی | 24 | فرانسه | 19 |
| آگوست | پاریس | 14 | فرانسه | 10 |
| سپتامبر | بوردو | 14 | فرانسه | 24 |
| اکتبر | دیژون | 4 | فرانسه | 2 |
بنابراین اتریبیوت ها کجا هستند؟ گفتیم: اتریبیوت داده یک توصیف کننده تک مقداری برای یک نقطه داده یا شی داده است. با توجه به اینکه نقاط داده در اینجا بر اساس ماه و شهر است، سایر فیلدها یا ستون ها حاوی توصیفات تک مقداری هستند و در نتیجه اتریبیوت محسوب می شوند.
هر ورودی تکی در ستون روز و کشور یک اتریبیوت است. اما “میزان بارش” یک اتریبیوت نیست. برای درک بهتر این اتریبیوت ها باید جمع مقایسه اتریبیوت های Aggregate و اندازه ها را بشناسیم.
مقایسه اتریبیوت های Aggregate و اتریبیوت های Single
یک فرق مهمی وجود دارد زمانی که از ” اتریبیوت” هم به معنای مقدار هر سلول و هم کل ستون (نام ستون) استفاده می کنید. به عنوان مثال ممکنه بگویید که فرانسه اتریبیوت ماه اکتبر در دیژون است و یا بگویید صفت کشور اتریبیوت ماه و شهر است. مورد اول یک اتریبیوت Single است در حالی که دومی اتریبیوت Aggregate می باشد.
مقایسه اتریبیوت ها و اندازه ها
در این مثال نمی توانیم “میزان بارش” را یک اتریبیوت در نظر بگیریم. دلیلش این است که مجموعه مشخصی از شناسه ها (ID) منحصر به فرد ندارد، یک دسته بندی نیست. به جای آن یک مقدار عددی ارائه می دهد که می تواند از نظر محاسبات ریاضی با سایر سطرها کار کند. اینجا به جای “اتریبیوت ها” به ستون هایی اشاره می کنیم که داده های عددی را به عنوان اندازه ها ارائه می دهند.
این ممکنه در ابتدا عجیب و غیرمنطقی به نظر برسد. اگر این عدد اطلاعاتی درباره شناسه منحصر به فرد ارائه دهد، بنابراین آنها هر دو توصیف کننده هستند، درسته؟ نه دقیقا. نکته مهمی که وجود دارد، اینه که می توانیم اعداد را در سطرهای بالا و پایین ضرب، تقسیم، جمع و تفریق کنیم. ID منحصر به فرد توسط اعداد ثابت قابل توصیف نیست اما اتریبیوت ها توصیف می کنند.
با این حال اگر ستون فقط شامل 1 و 0 باشد آنگاه می تواند یک دسته بندی باشند و به عنوان یک اتریبیوت در نظر گرفته شود زیرا نمی توانید از آنها در محاسبات عددی استفاده کنید.
سطرها به عنوان اتریبیوت ها
تا اینجا ستون ها را به عنوان اتریبیوت ها و اندازه ها را مورد بحث قرار دادیم اما در مورد سطرها چطور؟ آیا می توانیم به نوعی از IDهای منحصر به فرد به عنوان اتریبیوت و ویژگی استفاده کنیم؟ پاسخ بله است.
برای درک این موضوع باید به تعریف پیشفرض در مورد اتریبیوت ها برگردیم: آنها چیزی بیش از یک قطعه داده نیستند که داده دیگری را توصیف می کند.
به عنوان مثال می خواهیم بدانیم کدام شهر در آمریکا 13 سانتی متر بارندگی در روز 24 ام ماه داشته است. در این مورد، اتریبیوت مقدار سطر یعنی شهر هوستون است در حالیکه “ID منحصر به فرد” مربوط به آن ” 13 سانتی متر، آمریکا، روز 24ام” است. معیارهای جستجو مهم است. براساس نحوه فیلتر داده ها یک سطر می تواند به یک اتریبیوت و یک ستون به ID منحصر به فرد تبدیل شود.
چگونه برنامه نویس شویم؟ (9 نکته برای شروع و ورود به بازار کار)
بنابراین فقط یک شهر به روز 24 ام در امریکا با مقدار بارش 13 سانتی متر مرتبط است. در یک پایگاه داده بزرگتر احتمالا شهرهای مرتبط بیشتری پیدا خواهید کرد. این دلیل دیگری است که چرا می توانیم به صفات به عنوان single یا aggregate اشاره کنیم.
هنگام تجزیه و تحلیل داده ها هدف این است که با تلفیق و مقایسه سطرها و ستون ها، اطلاعات را از یک مجموعه داده به دست آوریم. برای تجزیه و تحلیل اعمال فقط یک اتریبیوت به یک ID منحصر به فرد خیلی مفید نیست. بنابراین صفات Aggregate در تجزیه و تحلیل لازم است.
معیارهای اتریبیوت های داده قابل استفاده در تجزیه و تحلیل
برای اینکه یک اتریبیوت داده برای تجزیه و تحلیل داده های بزرگ ارزشمند باشد باید معیارهای زیر را داشته باشد:
1- اتریبیوت باید در بیش از یک سطر یا ستون وجود داشته باشد (aggregate) مگر اینکه در فیلد خودش یکتا باشد. به عنوان مثال اگر یکی از شهرها در آلمان بود هنوز هم این اتریبیوت “کشور” خواهد بود.
2- مقدار صفت باید خود توصیف و واضح باشد یا توصیف متاداده (متدیتا) داشته باشد.
3- اگر اتریبیوت به عنوان توصیف کننده ID دیگری استفاده می شود نباید به یک ID نرمال سازی شود. در غیر این صورت، ممکنه تجزیه و تحلیل، ارتباطات نادرستی ایجاد کند.
تصور نکته سوم دشوار است. برای درک آن، پایگاه داده زیر را نگاه کنید:
| ID1 | presentID1 # | ID2 | presentID2 # |
|---|---|---|---|
| ID1 | 1 | ID2 | 6 |
| ID2 | 2 | ID3 | 5 |
| ID3 | 3 | ID4 | 4 |
| ID4 | 4 | ID5 | 3 |
| ID5 | 5 | ID6 | 2 |
| ID6 | 6 | ID7 | 1 |
این ساختار زمانی ایجاد می شود که بخواهیم با ادغام دو ID منحصر به فرد در یک جدول، آنها را با هم مقایسه کنیم. اما یک مشکلی وجود دارد: از آنجا که presentID2 # مقدار درست ID1 نیست، نمی توانیم آن را به عنوان یک اتریبیوت برای ID1 در نظر بگیریم.
برای اینکه presentID2 # به عنوان یک اتریبیوت برای ID1 مفید باشد، باید این مقادیر را مجدداً تغییر دهیم تا از درستی آن در ID1 مطمئن شویم. به همین دلیل است که ابتدا پایگاه داده ها را نرمال سازی می کنیم.
اتریبیوت های داده در مدل های داده
در زمینه مدل های داده، اتریبیوت داده ستون های جدول داده را نشان می دهند. به عنوان مثال یک مدل داده منطقی، کلید اصلی (ID یا شناسه منحصر به فرد) و نام ستون های اتریبیوت را نشان می دهد. چون همه گزینه های اتریبیوت را لیست نمی کند، این مثالی از اتریبیوت های aggregate است.
نمونه زیر یک مدل داده تجاری ساده است:
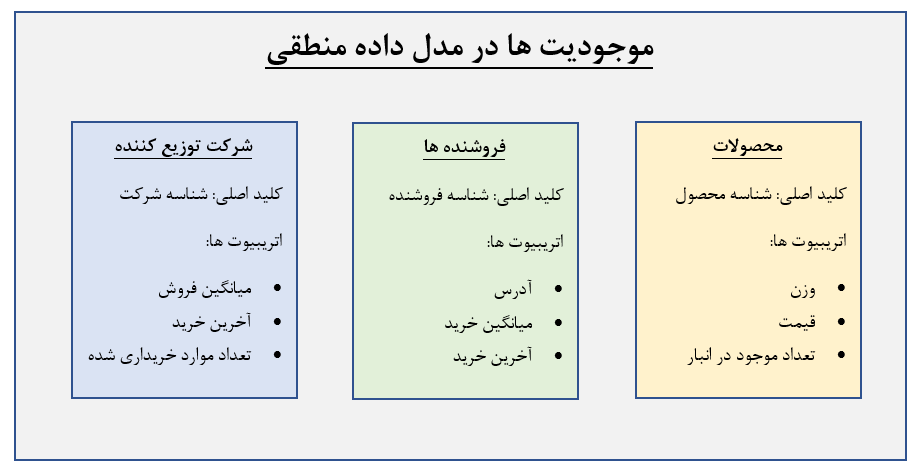
جعبه ها نشان دهنده جدول های داده می باشند، همانطور که می بینید کلید اصلی (ID منحصر به فرد) و نام اتریبیوت ها (سایر ستون) در آنها ساختاردهی شده اند.
اتریبیوت داده در HTML و jQuery
یک اتریبیوت داده در HTML و jQuery قالب یا عملکرد خاصی است که به یک شی اضافه می شود. یکی از ضروری ترین آنها اتریبیوت data-ID (شناسه-داده) است.
اتریبیوت data-ID چیست؟
به طور خلاصه هنگام ایجاد یک متغیر یا هر عنصر داده دیگری در کد می توانید یک شناسه (ID) عددی یا متنی به آن اختصاص دهید تا آن را با استفاده از “نام” id=به عنوان یک شی داده وارد کنید. در این زمینه ID داده یک اتریبیوت از عنصر است که عنصر را منحصر به فرد کرده و آن را برای استفاده های بعدی قابل شناسایی می کند.
به عنوان مثال، عنصر <object>… </object> را در نظر بگیرید. می توانیم یک اتریبیوت یا صفت data-ID در براکت های (تگ) اول به صورت زیر اضافه کنیم:
<object id=”name of object”>…<object>
اتریبیوت داده در پایتون
در پایتون هر شی که ایجاد می کنید، می تواند اتریبیوت هایی مانند نام، سن، ارتفاع و سایر توصیف کننده ها را داشته باشد. به عنوان مثال هنگام تعریف کلاس، برنامه نویس ممکنه آن را با ساختار زیر نامگذاری کند:
self.name = name
اتریبیوت داده در GIS
اشیای داده در GIS می توانند اتریبیوت های داده را دریافت کنند که مکان، چه چیزی و چرا برای شی داده را شبیه به یک پایگاه داده سنتی توصیف کند. گرچه GIS یک فریمورک است و زبان برنامه نویسی نیست. بنابراین اتریبیوت های GIS خروجی اسکریپت های پایتون، HTML و سایر موارد هستند.
اتریبیوت داده در Six Sigma
در اصول Six Sigma اتریبیوت های داده به همان شکل در پایگاه های داده سنتی تعریف می شوند. آنها اغلب نام ستون ها هستند، اما بسته به روش تحلیلگر برای سوال می توانند مقادیر سطر نیز باشند.
در ادامه: همه آموزشهای برنامه نویسی (رایگان)